目录
头部和尾部数据head() 与 tail()
import pandas as pd
data = {
"hello": [100, 200, 300, 400, 500, 600, 700, 800],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV1", "YYDataV2", "YYDataV3", "YYDataV4",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
print(df.head())
print(" ----------- ")
print(df.tail())

索引与列名 index与columns
import pandas as pd
data = {
"hello": [100, 200, 300, 400, 500, 600, 700, 800],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV1", "YYDataV2", "YYDataV3", "YYDataV4",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
print(df.index)
print(df.columns)

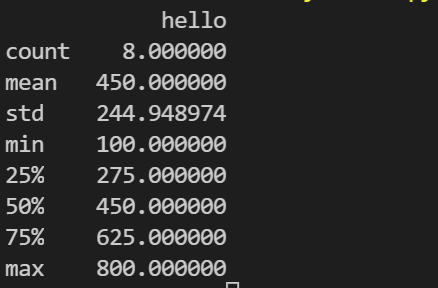
统计摘要 describe()
import pandas as pd
data = {
"hello": [100, 200, 300, 400, 500, 600, 700, 800],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV1", "YYDataV2", "YYDataV3", "YYDataV4",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
print(df.describe())
转置数据 T
import pandas as pd
data = {
"hello": [100, 200, 300, 400, 500, 600, 700, 800],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV1", "YYDataV2", "YYDataV3", "YYDataV4",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
print(df)
print(df.T)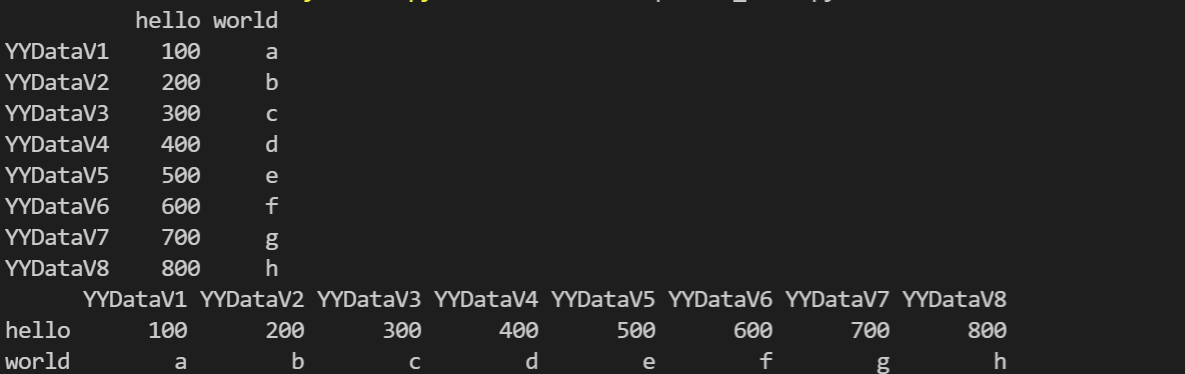
按轴排序 sort_index()
import pandas as pd
data = {
"hello": [100, 200, 300, 400, 500, 600, 700, 800],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV2", "YYDataV1", "YYDataV4", "YYDataV3",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
print(df.sort_index())

按值排序 sort_values()
import pandas as pd
data = {
"hello": [200, 100, 300, 400, 500, 600, 700, 800],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV1", "YYDataV2", "YYDataV3", "YYDataV4",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
print(df.sort_values(by='hello'))

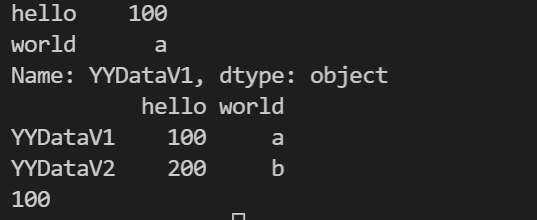
按标签选择 loc 与 at
import pandas as pd
data = {
"hello": [100, 200, 300, 400, 500, 600, 700, 800],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV1", "YYDataV2", "YYDataV3", "YYDataV4",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
# 选择一行
print(df.loc["YYDataV1"])
# 分片选择多行
print(df.loc["YYDataV1": "YYDataV3"])
# 选择某个值
print(df.at["YYDataV1", "hello"])

按位置选择 iloc 与iat
import pandas as pd
data = {
"hello": [100, 200, 300, 400, 500, 600, 700, 800],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV1", "YYDataV2", "YYDataV3", "YYDataV4",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
# 选择一行
print(df.iloc[0])
# 分片选择多行
print(df.iloc[0: 2])
# 选择某个值
print(df.iat[0, 0])
条件选择 > 与isin()
import pandas as pd
data = {
"hello": [100, 200, 300, 400, 500, 600, 700, 800],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV1", "YYDataV2", "YYDataV3", "YYDataV4",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
# 条件选择
print(df[df.hello > 400])
# 条件选择
print(df[df.hello.isin([400, 500])])
赋值 =
import pandas as pd
data = {
"hello": [100, 200, 300, 400, 500, 600, 700, 800],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV1", "YYDataV2", "YYDataV3", "YYDataV4",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
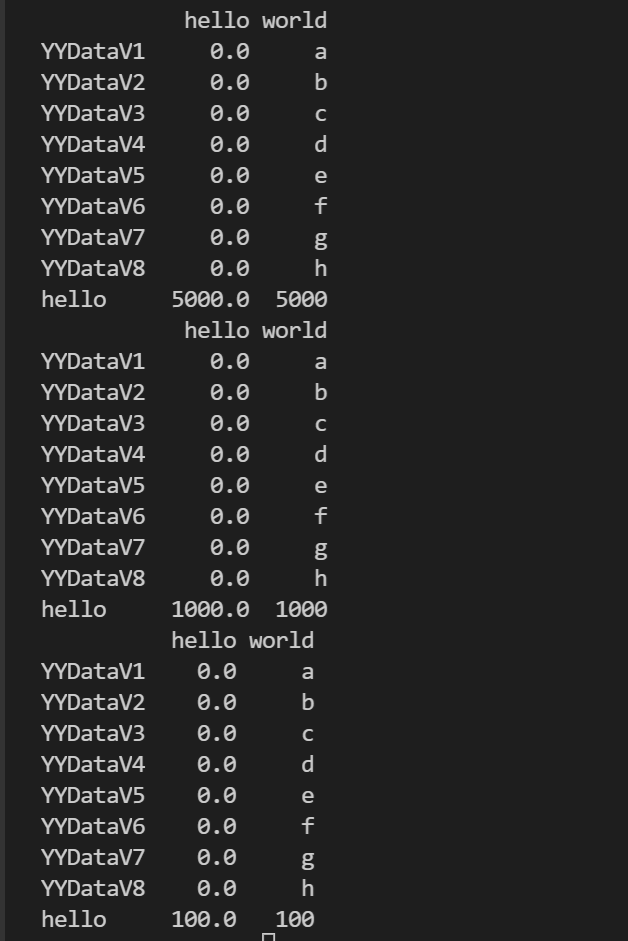
df['hello'] = 0
print(df)
df.at['hello'] = 5000
print(df)
df.loc['hello'] = 1000
print(df)
df[df.hello > 400] = 100
print(df)
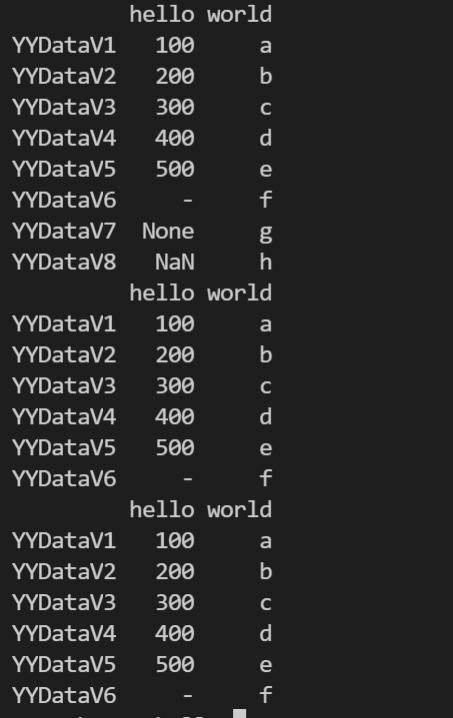
缺失值 np.nan
Pandas 主要用 np.nan 表示缺失数据。 计算时,默认不包含空值。
import imp
import pandas as pd
import numpy as np
data = {
"hello": [100, 200, 300, 400, 500, '-', None, np.nan],
"world": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
}
i = ["YYDataV1", "YYDataV2", "YYDataV3", "YYDataV4",
"YYDataV5", "YYDataV6", "YYDataV7", "YYDataV8"]
df = pd.DataFrame(data, index=i)
print(df)
# 删除缺失值
df = df.dropna()
print(df)
# 填充默认缺失值
df = df.fillna(value=5)
print(df)