部署规划
系统选型
因为kafka服务端代码是Scala语言开发的,因此属于JVM系的大数据框架,目前部署最多的3类操作系统主要由Linux ,OS X 和Windows,但是部署在Linux数量最多,为什么呢?因为I/O模型的使用和数据网络传输效率两点。
- 第一:Kafka新版本的Clients在设计底层网络库时采用了Java的Select模型,而在Linux实现机制是epoll,模型在redis中也是这几种,明确一点就是:kafka跑在Linux上效率更高,因为epoll取消了轮询机制,换成了回调机制,当底层连接socket数较多时,可以避免CPU的时间浪费。
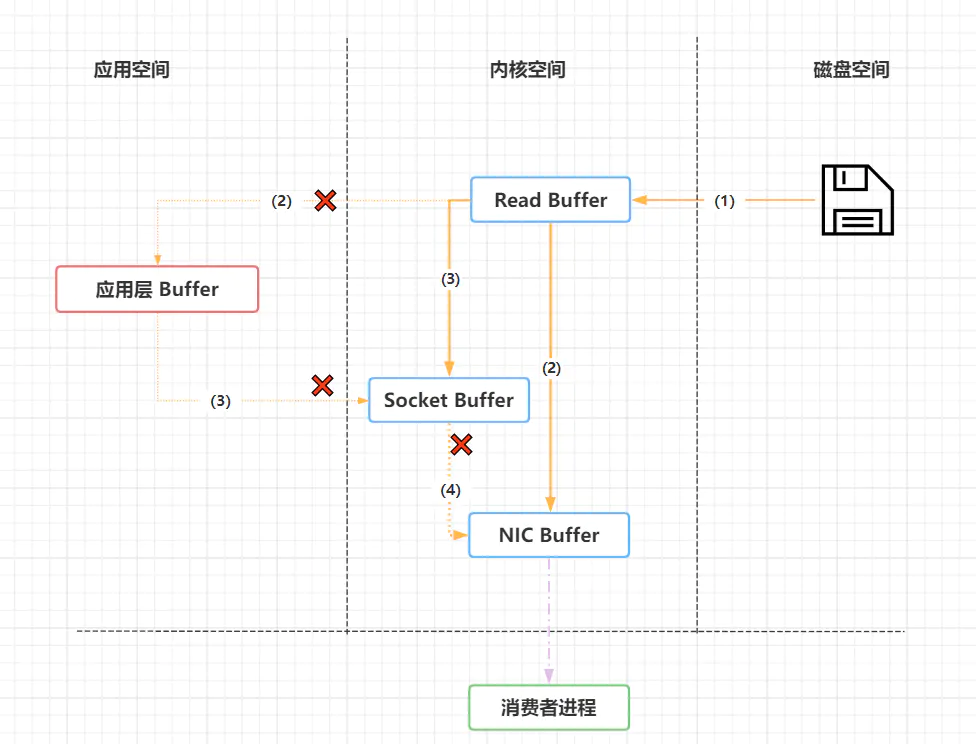
参考: IO模型 - 第二:网络传输效率上。kafka需要通过网络和磁盘进行数据传输,而大部分操作系统都是通过Java的FileChannel.transferTo方法实现,而Linux操作系统则会调用sendFile系统调用,也即零拷贝(Zero Copy 技术),避免了数据在内核地址空间和用户程序空间进行重复拷贝。
“零拷贝技术”只用将磁盘文件的数据复制到页面缓冲区一次,然后将数据从页面的缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面进行缓存),避免了重复复制操作
磁盘类型规划
- 机械磁盘(HDD)
一般机械磁盘寻道时间是毫秒级的,若有大量随机I/O,则将会出现指数级的延迟,但是kafka是顺序读写的,因此对于机械磁盘的性能也是不弱的,所以,基于成本问题可以考虑。
- 固态硬盘(SSD)
读写速度可观,没有成本问题可以考虑。
- JBOD (Just Bunch Of Disks )
经济实惠的方案,对数据安全级别不是非常非常高的情况下可以采用,建议用户在Broker服务器上设置多个日志路径,每个路径挂载在不同磁盘上,可以极大提升并发的日志写入速度。
- RAID 磁盘阵列
常见的RAID是RAID10,或者称为(RAID 1+0) 这种磁盘阵列结合了磁盘镜像和磁盘带化技术来保护数据,因为使用了磁盘镜像技术,使用率只有50%,注意,LinkedIn公司采用的就是RAID作为存储来提供服务的。那么弊端在什么地方呢?如果Kafka副本数量设置为3,那么实际上数据将存在6倍的冗余数据,利用率实在太低。因此,LinkedIn正在计划更改方案为JBOD.
参考: 服务器中硬盘JBOD模式和RAID0模式区别
磁盘容量规划
假设每天大约能够产生一亿条消息,假设副本replica设置为2 ,数据留存时间为1周,平均每条上报事件消息为1K左右,那么每天产生的消息总量为:1亿 乘 2 乘 1K 除以 1000 除以 1000 =200G磁盘。预留10%的磁盘空间,为210G。一周大约为1.5T。采用压缩,平均压缩比为0.5,整体磁盘容量为0.75T。
关联因素主要有:
- 新增消息数
- 副本数
- 是否启用压缩
- 消息大小
- 消息保留时间
内存容量规划
kafka对于内存的使用,并不过多依赖JVM 内存,而是更多的依赖操作系统的页缓存,consumer若命中页缓存,则不用消耗物理I/O操作。一般情况下,java堆内存的使用属于朝生夕灭的,很快会被GC,一般情况下,不会超过6G,对于16G内存的机器,文件系统page cache 可以达到10-14GB。
怎么设计page cache,可以设置为单个日志段文件大小,若日志段为10G,那么页缓存应该至少设计为10G以上。
堆内存最好不要超过6G。
CPU选择规划
kafka不属于计算密集型系统,因此CPU核数够多就可以,而不必追求时钟频率,因此核数选择最好大于8。
网络带宽决定Broker数量
带宽主要有1Gb/s 和10 Gb/s 。我们可以称为千兆位网络和万兆位网络。举例如下:
假设系统一天每小时都要处理1Tb的数据,选择1Gb/b带宽,那么需要选择多少机器呢?
假设网络带宽kafka专用,且分配给kafka服务器70%带宽,那么单台Borker带宽就是710Mb/s,但是万一出现突发流量问题,很容易把网卡打满,因此在降低1/3,也即240Mb/s。因为1小时处理1TTB数据,每秒需要处理292MB,1MB=8Mb,也就是2336Mb数据,那么一小时处理1TB数据至少需要2336/240=10台Broker数据。冗余设计,最终可以定为20台机器。
典型推荐
- cpu 核数 32
- 内存 32GB
- 磁盘 3TB 7200转 SAS盘三块
- 带宽 1Gb/s
参考: kafka生产规划
消费性能提升
增加分区
如果无法估算吞吐量的情况下:
一般来讲几个broker,那么至少就应该有几个分区,最小化保证每个broker都能参与到队列分流并行过程中。不过根据数据量的写入量,磁盘io的消耗占比,网络带宽的承载能力,我们可以适当增加每个broker的分区数,可以用每台broker分区最小数的倍数进行设置并测试吞吐,例如3,6,9,12…但总之不应调得过多,因为过多的分区数,会带来资源管理上的消耗,清除日志时间变长,集群broker故障后分区leader重选时间变长,客户端消费端线程数需求增加,甚至导致连接所需的socket消耗增加。
- 分区数过多的利弊:
- 客户端/服务器端需要使用的内存就越多
- 文件句柄的开销
- 越多的分区可能增加端对端的延迟
- 降低高可用性
如果可以估算出吞吐量,建议partition数量的计算:
在partition级别上达到均衡负载是实现吞吐量的关键,合适的partition数量可以达到高度并行读写和负载均衡的目的,需要根据每个分区的生产者和消费者的目标吞吐量进行估计。
可以遵循一定的步骤来确定分区数:根据某个topic日常"接收"的数据量等经验确定分区的初始值,然后测试这个topic的producer吞吐量和consumer吞吐量。假设它们的值分别是Tp和Tc,单位可以是MB/s。然后假设总的目标吞吐量是Tt,那么numPartitions = Tt / max(Tp, Tc)
说明:Tp表示producer的吞吐量。测试producer通常是很容易的,因为它的逻辑非常简单,就是直接发送消息到Kafka就好了。Tc表示consumer的吞吐量。测试Tc通常与应用消费消息后进行什么处理的关系更大,相对复杂一些。
为什么多个分区能起到负载均衡的作用?

- 分区副本分配逻辑规则如下:
- 在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
- 上述图Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。
- 上述图种每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
多个分区的多个leader分区可以在多个broker上,就可以均匀分配负载。
- 分区副本分配算法如下:
- 将所有N Broker和待分配的i个Partition排序.
- 将第i个Partition分配到第(i mod n)个Broker上.
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.
参考:Kafka集群partitions/replicas默认分配解析
关闭自动提交enable.auto.commit
参数enable.auto.commit设置是否周期性自动提交offset。如果在代码中手动维护偏移量,则需要将此值设置为false。参数auto.commit.interval.ms如果设置了自动提交enable.auto.commit为true,那么该参数生效,提交间隔默认为5秒 (偏移量手工提交可以按需减少分区偏移量的更新,有利于提升消费速度)
设置最大拉取数量max.poll.records
控制单次调用call方法能够返回的记录数量,帮助控制在轮询里需要处理的数据量。
大量消息的场景下可减少拉取消息的次数
max.poll.records 表示每次默认拉取消息条数,默认值为 500。
必须满足以下公式:
perTimes * 500 < max.poll.interval.ms =300000,
perTimes:表示每条小时处理时长
max.poll.interval.ms:表示消费者处理消息逻辑的最大时间,对于某些业务来说,处理消息可能需要很长时间,比如需要 1 分钟,那么该参数就需要设置成大于 1分钟的值,否则就会被 Coordinator 剔除消息组然后重平衡.
设置最小字节数fetch.min.bytes
消费者从服务器获取记录的最小字节数,broker收到消费者拉取数据的请求的时候,如果可用数据量小于设置的值,那么broker将会等待有足够可用的数据的时候才返回给消费者,这样可以降低消费者和broker的工作负载。
因为当主题不是很活跃的情况下,就不需要来来回回的处理消息,如果没有很多可用数据,但消费者的CPU 使用率却很高,那么就需要把该属性的值设得比默认值大。如果消费者的数量比较多,把该属性的值设置得大一点可以降低broker 的工作负载
设置最大等待时间fetch.max.wait.ms
fetch.min.bytes设置了broker返回给消费者最小的数据量,而fetch.max.wait.ms设置的则是broker的等待时间,两个属性只要满足了任何一条,broker都会将数据返回给消费者,也就是说举个例子,fetch.min.bytes设置成1MB,fetch.max.wait.ms设置成1000ms,那么如果在1000ms时间内,如果数据量达到了1MB,broker将会把数据返回给消费者;如果已经过了1000ms,但是数据量还没有达到1MB,那么broker仍然会把当前积累的所有数据返回给消费者。
缓冲区设置 receive.buffer.bytes + send.buffer.bytes
socket 在读写数据时用到的TCP 缓冲区也可以设置大小。如果它们被设为-1 ,就使用操作系统的默认值。如果生产者或消费者与broker 处于不同的数据中心内,可以适当增大这些值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。
开启压缩compression.type
此为 Kafka 中端到端的块压缩功能。如果启用,数据将由 producer 压缩,以压缩格式写入服务器,并由 consumer 解压缩。压缩将提高 consumer 的吞吐量,但需付出一定的解压成本。这在跨数据中心镜像数据时尤其有用。
也就是说,Kafka 的消息压缩是指将消息本身采用特定的压缩算法进行压缩并存储,待消费时再解压。
我们知道压缩就是用时间换空间,其基本理念是基于重复,将重复的片段编码为字典,字典的 key 为重复片段,value 为更短的代码,比如序列号,然后将原始内容中的片段用代码表示,达到缩短内容的效果,压缩后的内容则由字典和代码序列两部分组成。解压时根据字典和代码序列可无损地还原为原始内容。注:有损压缩不在此次讨论范围。
通常来讲,重复越多,压缩效果越好。比如 JSON 是 Kafka 消息中常用的序列化格式,单条消息内可能并没有多少重复片段,但如果是批量消息,则会有大量重复的字段名,批量中消息越多,则重复越多,这也是为什么 Kafka 更偏向块压缩,而不是单条消息压缩。
参考:Kafka消息的压缩机制
- 消息压缩类型
目前 Kafka 共支持四种主要的压缩类型:Gzip、Snappy、Lz4 和 Zstd。关于这几种压缩的特性:










