VOA英文网有中英对照版 《权力的游戏》 http://www.tingvoa.com/html/454618.html,但是只能在线看,而且每次不小段的太不方便了,想把它爬下来整理成大篇的,放到kindle上慢慢看。手工点了几页,每页复制到文本文件里,工作量太大了。于是就有了自己写个爬虫自动抓取的想法。说干就干。
http://www.tingvoa.com/html/454618.html 先分析它的HTML源:

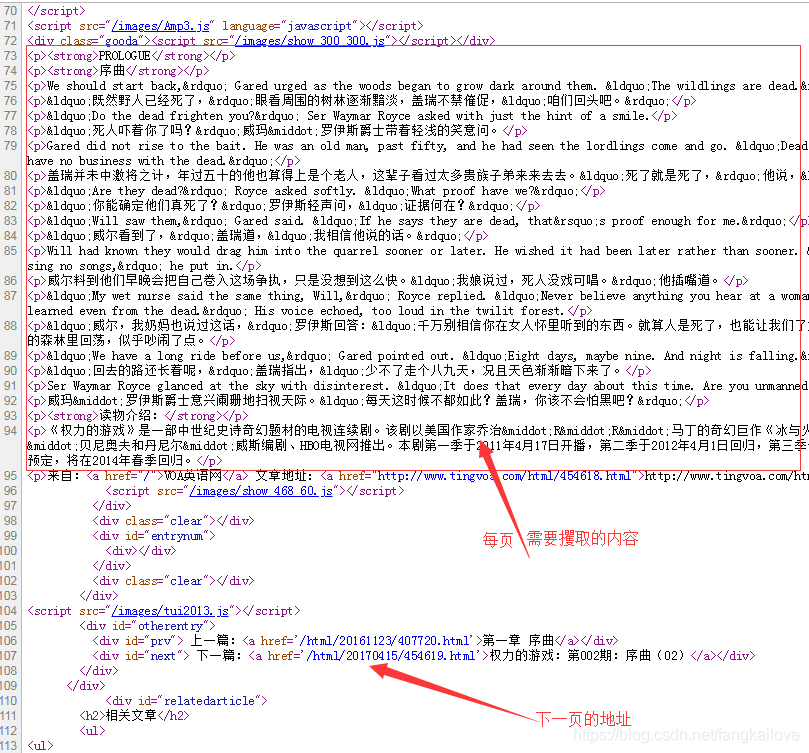
程序的功能就是要取每页特定部分的内容,剔除掉不要的内容,对取到的内容加工写入txt文件,并抓取下一页的地址。一页一页循环抓取。。
主要代码如下:
#!/usr/bin/python
# -*- coding: gbk -*-
# by gnolux 20190524
# email: fangkailove@yeah.net
from urllib import request
import re
url = 'http://www.tingvoa.com/html/454618.html'
title = '权力的游戏:第001期:restart'
for page in range(0,1210):
response = request.urlopen(url)
html = response.read()
html = html.decode("utf-8")
rstr = r'(<p>.*?</p>)'
s=re.findall(rstr,html,re.S)
for i in range(len(s)):
if s[i].startswith("<p>《权力的游戏》是一部"):
s[i]=''
if s[i].startswith("<p>背景介绍:"):
s[i]='\n-----------------\n'
if s[i].startswith("<p>来自"):
s[i]=''
#ct = '\n'.join(s)
title=title.split(':')[2]
print(title)
#print(url)
#print(ct)
with open('d:/%s.txt'%title, 'w') as f:
f.write("<h>%s</h>"%title)
f.write("<p>%s</p>"%url)
f.writelines(s)
rstr = r'<div id="next"> 下一篇:<a href=\'(.*?)\'>(.*?)</a>'
s=re.findall(rstr,html,re.S)
if len(s) == 1:
url,title = s[0]
url='http://www.tingvoa.com'+url
else:
print(ct)
brea
上述写文件部分,没有合并到一个文本文件中,而是每个单独一个文件,是因为网页发布不是完全有序的。以章节作文件名,全爬下来后,按文件名重排序并合并,就能得到有序的完整书内容了。
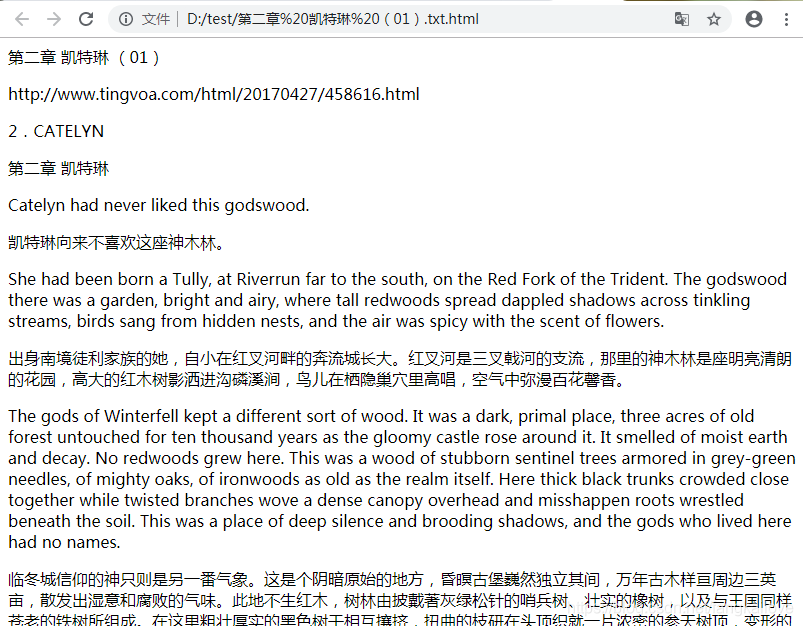
看爬下的结果: