Abstract
更多关注
计算机视觉-Paper&Code - 知乎
paper code
paper
- HRNet由微软亚洲研究院和中科大提出,已发表于CVPR2019
- 王井东 IEEE fellow 目前已经加入百度AIGroup作为CV首席架构师,主要研究领域为姿态估计、分割检测工业界学术界大牛。
- 回顾上次分享的HRNet,在保持高分辨和高语义信息下虽然得到了很好的效果,但是没有下采样阶段,模型复杂度高,部署困难的问题。对此团队继续推出了轻量化的LiteHRNet
总结来说文章主要以下创新贡献
- 借鉴Shuffle Block, 使用SB代替了原先的RB, 使用depthwise卷积代替fuse layer中的传统卷积,得到Naive Lite HRNet,大大减少计算量
- 提出并使用Conditional Channel Weighting操作代替第一点中提到的1*1 pointwise卷积得到LiteHRNet
Related Work
ShuffleNet
ShuffleNet主要通过以下三个操作来修改residual block,详见子韵如初:Paper Reading - Model系列 - ShuffleNet
- channel shuffle
- pointwise group convolutions
- depthwise separable convolution
Mediating spatial information loss
传统encoder-decoder架构下都需要从低分辨率中恢复空间信息,类似SegNet则会去对不同分辨率的输入采用不同的计算,以降低整体复杂性。BiSeNet通过采用两个分支网络去将细节信息和上下文信息整合起来。HRNet则一直保持着高分辨率特征图
Convolutional weight generation and mixing
该领域主要通过动态生成以输入为条件的conv kernel。常见的几个工作方向为
- MetaNet采用元学习器来生成权重以学习跨任务知识。SOLOV2将此设计应用于实例分割任务,为每个实例生成mask sub-network的参数
- SENet使用全局信息来激发或抑制channel的权重。(详见子韵如初:Paper Reading - 模型结构系列 - The Last Champion Squeeze-and-Excitation)
- CBAM相比为se的channel attention还利用了空间注意力来细化特征。
- 本文的conditional channel weighting可以被视为conditional channel-wise 1 × 1 convolution。大大减少了计算量,还能够跨通道交换信息。
Conditional architecture
Dilated/Deformable Convolution 、SkipNet等能通过利用逻辑可控制来动态决定网络结构的宽度、深度、kernals
空洞卷积,不通过pooling下采样就能得到更大的感受野
相比传统卷积,deformable可形变卷积需要自适应学习每个像素点的采样点的offset,根据偏移量进行采样然后加权求和得到feature map
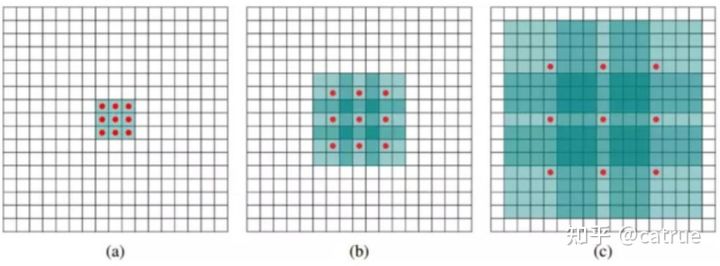
如图dialted rate 分别为1,2,4
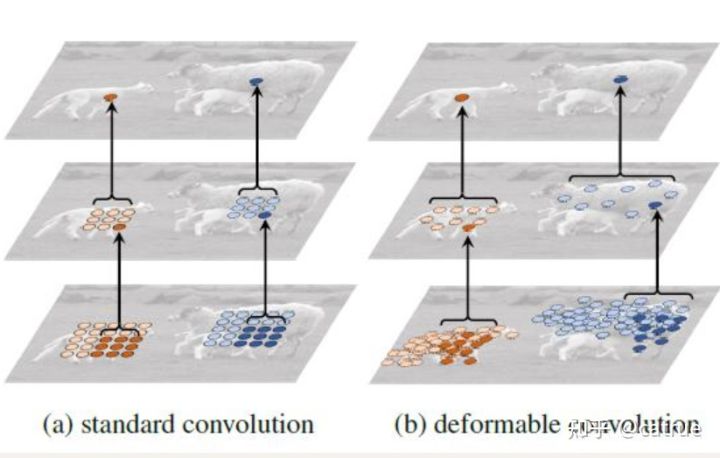
deformable conv
Algorithm

Naive Lite-HRNet
- 将stem中第二个3*3卷积替换为dwconv
- 把所有残差block都替换为shuffleblock
- 在fuse layer中的卷积都替换成可分离卷积
LiteHRNet
想要进一步优化,难题就是如何替换掉占大部分算力的1*1卷积了
1*1卷积主要是为了跨通道交换信息,因此同样替换为深度卷积对跨通道的信息交换没有影响
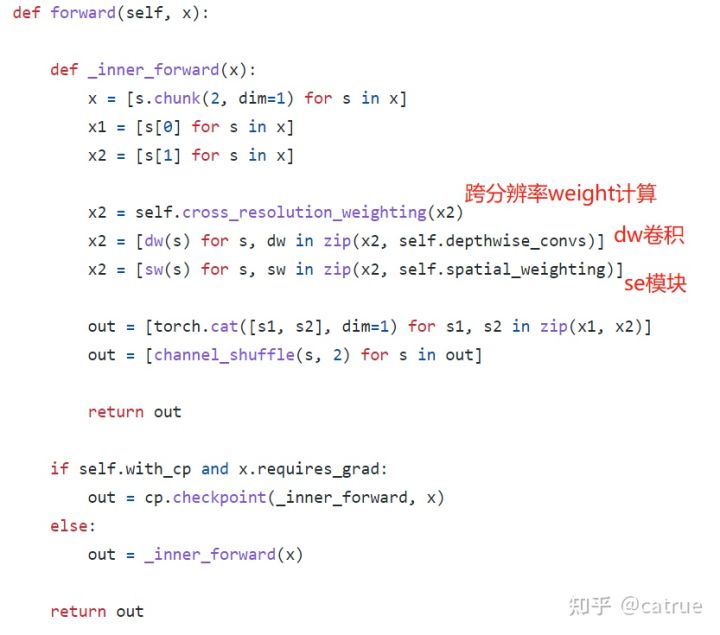
文章提出Conditional channel weighting,该方法复杂度与通道数成线性关系,并且低于pointwise卷积的二次时间复杂度。不同于常规卷积的权重作为模型参数学习,该模块的权重以输入特征图为基础,通过轻量级模块跨通道计算得到。同时基于HRNet模块能得到跨分辨率和跨通道的信息
其中Conditional channel weighting可分为以下两个操作:
- Cross-resolution Weight Computation. 对于第s个分支中位置i处的特征值,计算公式为:


- Spatial Weight Computation, 同样对于s分支为


总体block实现如图
Experiment
在保证性能的情况下FLOPs明显减少
值得一提的是,作者继续做了消融实验,使用文章提出的模块替换 其他网络的1×1 卷积,也得到了不错的结果











