一、分类模型的评估指标:样本不均匀问题
### --- 分类模型的评估指标
~~~ # 样本不均匀问题
~~~ 对于分类问题,永远都逃不过的一个痛点就是样本不均衡问题。~~~ 样本不均衡是指在一组数据集中,标签的一类天生占有很大的比例,
~~~ 但我们有着捕捉出某种特定的分类的需求的状况。
~~~ 比如,我们现在要对潜在犯罪者和普通人进行分类,潜在犯罪者占总人口的比例是相当低的,
~~~ 也许只有2%左右,98%的人都是普通人,而我们的目标是要捕获出潜在犯罪者。
~~~ 这样的标签分布会带来许多问题。
~~~ 首先,分类模型天生会倾向于多数的类,让多数类更容易被判断正确,少数类被牺牲掉。
~~~ 因为对于模型而言,样本量越大的标签可以学习的信息越多,
~~~ 算法就会更加依赖于从多数类中学到的信息来进行判断。如果我们希望捕获少数类,模型就会失败。~~~ 其次,模型评估指标会失去意义。这种分类状况下,即便模型什么也不做,
~~~ 全把所有人都当成不会犯罪的人,准确率也能非常高,这使得模型评估指标 accuracy 变得毫无意义,
~~~ 根本无法达到我们的“要识别出会犯罪的人”的建模目的。
~~~ 所以现在,我们首先要让算法意识到数据的标签是不均衡的,
~~~ 通过施加一些惩罚或者改变样本本身,来让模型向着捕获少数类的方向建模。
~~~ 我们可以使用上采样和下采样来达成这个目的,所用的方法叫做 SMOTE,
~~~ 这种方法通过将少数类的特征重新组合,创造出更多的少数类样本。
~~~ 但这些采样方法会增加样本的总数,对于决策树这个样本总是对计算速度影响巨大的算法来说,
~~~ 我们完全不想轻易地增加样本数量,
~~~ 所以我们要寻求另一条路:改进我们的模型评估指标,使用更加针对于少数类的指标来优化模型。~~~ class_weight
~~~ 在决策树中,存在着调节样本均衡的参数:class_weight 和接口 fit 中可以设定的 sample_weight。
~~~ 在决策树中,参数 class_weight 默认 None,此模式表示假设数据集中的所有标签是均衡的,
~~~ 即自动认为标签的比例是 1:1。
~~~ 所以当样本不均衡的时候,
~~~ 我们可以使用形如 {"标签的值 1":权重 1,"标签的值 2":权重 2} 的字典来输入真实的样本标签比例,来让算法意识到样本是不平衡的。
~~~ 或者使用”balanced“模式,
~~~ 有了权重之后,样本量就不再是单纯地记录数目,而是受输入的权重影响了,
~~~ 因此这时候剪枝,就需要搭配 min_ weight_fraction_leaf 这个基于权重的剪枝参数来使用。
~~~ 另请注意,
~~~ 基于权重的剪枝参数(例如 min_weight_ fraction_leaf)
~~~ 将比不知道样本权重的标准(比如min_samples_leaf)更少偏向主导类。
~~~ 如果样本是加权的,则使用基于权重的预修剪标准来更容易优化树结构,
~~~ 这确保叶节点至少包含样本权重的总和的一小部分。二、混淆矩阵
### --- 混淆矩阵
~~~ 从上一节的例子中可以看出,如果我们的目标是希望尽量捕获少数类,
~~~ 那准确率这个模型评估逐渐失效,所以我们需要新的模型评估指标来帮助我们。
~~~ 如果简单来看,其实我们只需要查看模型在少数类上的准确率就好了,
~~~ 只要能够将少数类尽量捕捉出来,就能够达到我们的目的。~~~ 但此时,新问题又出现了,我们对多数类判断错误后,
~~~ 会需要人工甄别或者更多的业务上的措施来一一排除我们判断错误的多数类,这种行为往往伴随着很高的成本。
~~~ 比如银行在判断”一个申请信用卡的客户是否会出现违约行为“的时候,
~~~ 如果一个客户被判断为”会违约“,这个客户的信用卡申请就会被驳回,
~~~ 如果为了捕捉出”会违约“的人,大量地将”不会违约“的客户判断为”会违约“的客户,
~~~ 就会有许多无辜的客户的申请被驳回。信用卡对银行来说意味着利息收入,
~~~ 而拒绝了许多本来不会违约的客户,对银行来说就是巨大的损失。
~~~ 同理,大众在召回不符合欧盟标准的汽车时,如果为了找到所有不符合标准的汽车,
~~~ 而将一堆本来符合标准了的汽车召回,这个成本是不可估量的。~~~ 也就是说,单纯地追求捕捉出少数类,就会成本太高,而不顾及少数类,又会无法达成模型的效果。
~~~ 所以在现实中,我们往往在寻找捕获少数类的能力和将多数类判错后需要付出的成本的平衡。
~~~ 如果一个模型在能够尽量捕获少数类的情况下,还能够尽量对多数类判断正确,则这个模型就非常优秀了。
~~~ 为了评估这样的能力,我们将引入新的模型评估指标:混淆矩阵来帮助我们。~~~ 混淆矩阵是二分类问题的多维衡量指标体系,在样本不平衡时极其有用。
~~~ 在混淆矩阵中,我们将少数类认为是正例,多数类认为是负例。
~~~ 在决策树,随机森林这些分类算法里,即是说少数类是 1,多数类是 0。
~~~ 在 SVM 里,就是说少数类是 1,多数类是-1。~~~ 普通的混淆矩阵,一般使用{0,1}来表示。
~~~ 混淆矩阵阵如其名,十分容易让人混淆,在许多教材中,
~~~ 混淆矩阵中各种各样的名称和定义让大家难以理解难以记忆。
~~~ 我为大家找出了一种简化的方式来显示标准二分类的混淆矩阵,如图所示:
### --- 其中:
~~~ 行代表预测情况,列则表示实际情况。
~~~ 预测值为 1,记为 P(Positive)
~~~ 预测值为 0,记为 N(Negative)
~~~ 预测值与真实值相同,记为 T(True)
~~~ 预测值与真实值相反,记为 F(False)
### --- 因此矩阵中四个元素分别表示:
~~~ TP(True Positive): 真实为 1,预测作 1
~~~ FN(False Negative): 真实为 1,预测作 0
~~~ FP(False Positive): 真实为 0,预测作 1
~~~ TN(True Negative): 真实为 0,预测作 0~~~ 基于混淆矩阵,我们有一系列不同的模型评估指标,这些评估指标的范围都在[0,1]之间,
~~~ 所有以 11 和00 为分子的指标都是越接近 1 越好,
~~~ 所以以 01 和 10 为分子的指标都是越接近 0 越好。
~~~ 对于所有的指标, 我们用橙色表示分母,用绿色表示分子,则我们有:
### --- 模型整体效果:准确率
~~~ # 准确率 Accuracy 就是所有预测正确的所有样本除以总样本,通常来说越接近 1 越好。
~~~ 记住少数类是1,多数类是 0
### --- 精确度 Precision
~~~ 精确度 Precision,又叫查准率,表示在所有预测结果为 1 的样例数中,
~~~ 实际为 1 的样例数所占比重。精确度越低,意味着 01 比重很大,
~~~ 则代表你的模型对多数类 0 误判率越高,误伤了过多的多数类。
~~~ 为了避免对多数类的误伤,需要追求高精确度。
~~~ 精确度是” 将多数类判错后所需付出成本的衡量’’。#所有判断正确并确实为 1 的样本 / 所有被判断为 1 的样本
#对于没有 class_weight 的决策树来说:
Precision_1 = (Ytest[Ytest == clf_01.predict(Xtest)] ==
1).sum()/(clf_01.predict(Xtest) == 1).sum()
Precision_1
#对于有 class_weight 的决策树来说:
Precision_2 = (Ytest[Ytest == clf_02.predict(Xtest)] ==
1).sum()/(clf_02.predict(Xtest) == 1).sum()
Precision_2
~~~ # 输出参数
0.6363636363636364
0.68~~~ 在现实的样本不平衡例子中,
~~~ 当每一次将多数类判断错误的成本非常高昂的时候(比如大众召回车辆的例子),我们会追求高精确度。
~~~ 当然了,如果我们的目标是不计一切代价捕获少数类,那我们并不在意精确度,而在意召回率。
### --- 召回率 Recall
~~~ 召回率 Recall,又被称为敏感度(sensitivity),真正率,查全率,
~~~ 表示所有真实为 1 的样本中,被我们预测正确的样本所占的比例。
~~~ 召回率越高,代表我们尽量捕捉出了越多的少数类。
~~~ 召回率越低,代表我们没有捕捉出足够的少数类。
#所有 predict 为 1 并且正确的点 / 全部为 1 的点的比例
#对于没有 class_weight 的决策树来说:
(ytest[ytest == clf.predict(Xtest)] == 1).sum()/(ytest == 1).sum()
#对于有 class_weight 的决策树来说:
(ytest[ytest == wclf.predict(Xtest)] == 1).sum()/(ytest == 1).sum()
~~~ # 输出参数
0.4827586206896552
0.5862068965517241~~~ 可以看出,做样本平衡之前,我们只成功捕获了 48%左右的少数类点,而做了样本平衡之后的模型,
~~~ 捕捉出了 58%的少数类点。召回率可以帮助我们判断,我们是否捕捉除了全部的少数类,
~~~ 所以又叫做查全率。
~~~ 如果我们希望不计一切代价,找出少数类(比如找出潜在犯罪者的例子),
~~~ 那我们就会追求高召回率,相反如果我们的目标不是尽量捕获少数类,那我们就不需要在意召回率。~~~ 注意召回率和精确度的分子是相同的(都是 11),只是分母不同。
~~~ 而召回率和精确度是此消彼长的,
~~~ 两者之间的平衡代表了捕捉少数类的需求和尽量不要误伤多数类的需求的平衡。
~~~ 究竟要偏向于哪一方,取决于我们的业务需求:究竟是误伤多数类的成本更高,
~~~ 还是无法捕捉少数类的代价更高。### --- F1 measure
~~~ 为了同时兼顾精确度和召回率,
~~~ 我们创造了两者的调和平均数作为考量两者平衡的综合性指标,称之为F1 measure。
~~~ 两个数之间的调和平均倾向于靠近两个数中比较小的那一个数,
~~~ 因此我们追求尽量高的 F1 measure,能够保证我们的精确度和召回率都比较高。
~~~ F1 measure 在[0,1]之间分布,越接近 1 越好。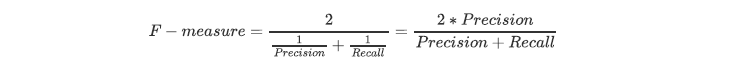
### --- 假负率
~~~ 从 Recall 延申出来的另一个评估指标叫做假负率(False Negative Rate),
~~~ 它等于 1 - Recall,用于衡量
~~~ 所有真实为 1 的样本中,被我们错误判断为 0 的,通常用得不多。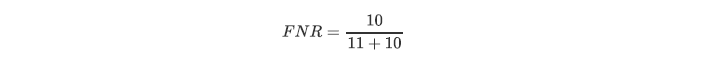
### --- ROC 曲线
~~~ ROC 的全称是 Receiver Operating Characteristic Curve,其主要的分析方法就是画这条特征曲线。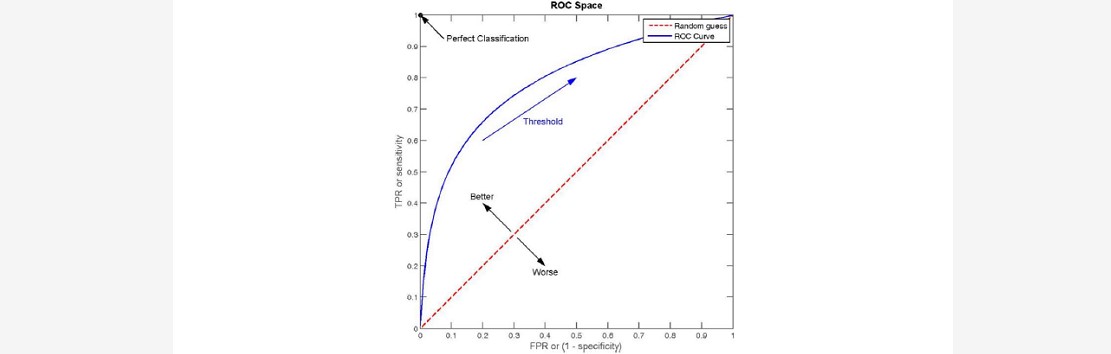
~~~ 该曲线的横坐标为假正率(False Positive Rate, FPR), N 是真实负样本的个数,
~~~ FP 是 N 个负样本中被分类器器预测为正样本的个数。
~~~ 纵坐标为召回率,真正率(True Positive Rate, TPR):
~~~ P 是真实正样本的个数,TP 是 P 个正样本中被分类器器预测为正样本的个数。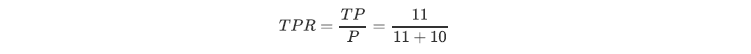
### --- sklearn 中的混淆矩阵类 | 含义 |
sklearn.metrics.confusion_matrix | 混淆矩阵 |
sklearn.metrics.accuracy_score | 准确率accuracy |
sklearn.metrics.precision_score | 精确度precision |
sklearn.metrics.recall_score | 召回率recall |
sklearn.metrics.precision_recall_curve | 精确度-召回率平衡曲线 |
sklearn.metrics.f1_score | F1 measure |
### --- 混淆矩阵
metrics.confusion_matrix(Ytest,clf_01.predict(Xtest))
metrics.confusion_matrix(Ytest,clf_02.predict(Xtest))
~~~ # 输出参数
array([[183, 8], [ 15, 14]], dtype=int64)
array([[183, 8], [ 12, 17]], dtype=int64)### --- 准确率
~~~ # Precision
metrics.precision_score(Ytest,clf_01.predict(Xtest))
metrics.precision_score(Ytest,clf_02.predict(Xtest))
~~~ # 输出参数
0.6363636363636364
0.68### --- 召回率
~~~ # Recall
metrics.recall_score(Ytest,clf_01.predict(Xtest))
metrics.recall_score(Ytest,clf_02.predict(Xtest))
~~~ # 输出参数
0.4827586206896552
0.5862068965517241### --- F 值
~~~ # F-measure
metrics.f1_score(Ytest,clf_01.predict(Xtest))
metrics.f1_score(Ytest,clf_02.predict(Xtest))
~~~ # 输出参数
0.5490196078431373
0.6296296296296295Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor










