一、监督学习算法:KNN/K近邻算法:算法原理
### --- KNN/K近邻算法
~~~ # 算法原理
~~~ 它的本质是通过距离判断两个样本是否相似,如果距离够近就认为他们足够相似属于同一类别。
~~~ 当然只对比一个样本是不够的,误差会很大,我们需要找到离其最近的 k 个样本,
~~~ 并将这些样本称之 为「近邻」(nearest neighbor)。对这 k 个近邻,
~~~ 查看它们的都属于何种类别(这些类别我们称作「标签」 (labels))。
~~~ 然后根据“少数服从多数,一点算一票”原则进行判断,
~~~ 数量最多的的标签类别就是新样本的标签类别。
~~~ 其中涉及到的原理是“越相近越相似”,这也是KNN的基本假设。### --- 实现过程
~~~ 假设 X_test 待标记的数据样本,X_train 为已标记的数据集。
~~~ 遍历已标记数据集中所有的样本,计算每个样本与待标记点的距离,
~~~ 并把距离保存在 Distance 数组中。
~~~ 对 Distance 数组进行排序,取距离最近的 k 个点,记为 X_knn.
~~~ 在 X_knn 中统计每个类别的个数,即 class0 在 X_knn 中有几个样本,
~~~ class1 在 X_knn 中有几个样本等。
~~~ 待标记样本的类别,就是在 X_knn 中样本个数最多的那个类别。### --- 距离的确定
~~~ 该算法的「距离」在二维坐标轴就表示两点之间的距离,计算距离的公式有很多。
~~~ 我们常用欧拉公式,即“欧氏距离”。回忆一下,一个平面直角坐标系上,
~~~ 如何计算两点之间的距离?
~~~ 一个立体直角坐标系上,又如何计算两点之间的距离?
~~~ 当特征数量有很多个形成多维空间时,再用上述的写法就不方便了,我们换一个写法,
~~~ 用 X 加下角标的方式表示特征维度。则在 n 维空间中,有两个点 A 和 B,它们的坐标分别为: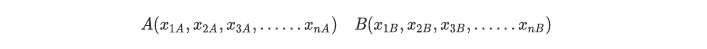
~~~ 则 A 和 B 两点之间的欧氏距离的基本计算公式如下:
~~~ 而在我们的机器学习中,坐标轴上的值x1, x2,x3,……xn 正是我们样本数据上的 n 个特征。
二、算法的优缺点
### --- 算法的优缺点
~~~ # 算法参数是 k,k 可以理解为标记数据周围几个数作为参考对象,参数选择需要根据数据来决定。
~~~ k 值越大,模型的偏差越大,对噪声数据越不敏感。
~~~ k 值很大时,可能造成模型欠拟合。
~~~ k 值越小,模型的方差就会越大。
~~~ 但是 k 值太小,容易过拟合。三、算法的变种
### --- 算法的变种
~~~ # 变种一:
~~~ 默认情况下,在计算距离时,权重都是相同的,
~~~ 但实际上我们可以针对不同的邻居指定不同的距离权重,比如距离越近权重越高。
~~~ 这个可以通过指定算法的 weights 参数来实现。
~~~ # 变种二:
~~~ 使用一定半径内的点取代距离最近的 k 个点在 scikit-learn 中,
~~~ RadiusNeighborsClassifier 实现了这种算法的变种。
~~~ 当数据采样不均匀时,该算法变种可以取得更好的性能。四、Python代码实现
### --- Python代码实现
~~~ # 导入相关包
#全部行都能输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 解决坐标轴刻度负号乱码
plt.rcParams['axes.unicode_minus'] = False
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Simhei']
plt.style.use('ggplot')
# plt.figure(figsize=(2,3),dpi=720)~~~ # 构建已经分类好的原始数据集
~~~ 首先随机设置十个样本点表示十杯酒,这里取了部分样本点。
~~~ 为了方便验证,这里使用 Python 的字典 dict 构建数据集,
~~~ 然后再将其转化成 DataFrame 格式。rowdata = {'颜色深度':
[14.13,13.2,13.16,14.27,13.24,12.07,12.43,11.79,12.37,12.04],
'酒精浓度': [5.64,4.28,5.68,4.80,4.22,2.76,3.94,3.1,2.12,2.6],
'品种': [0,0,0,0,0,1,1,1,1,1]}
# 0 代表 “黑皮诺”,1 代表 “赤霞珠”
wine_data = pd.DataFrame(rowdata)
wine_data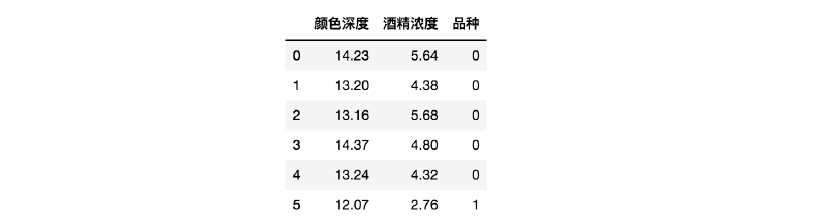
X = np.array(wine_data.iloc[:,0:2]) #我们把特征(酒的属性)放在X
y = np.array(wine_data.iloc[:,-1]) #把标签(酒的类别)放在Y
#探索数据,假如我们给出新数据[12.03,4.1] ,你能猜出这杯红酒是什么类别么?
new_data = np.array([12.03,4.1])
plt.scatter(X[y==1,0], X[y==1,1], color='red', label='赤霞珠') #画出标签y为1的、关于“赤霞珠”的散点
plt.scatter(X[y==0,0], X[y==0,1], color='purple', label='黑皮诺') #画出标签y为0的、关于“黑皮诺”的散点
plt.scatter(new_data[0],new_data[1], color='yellow') # 新数据点
new_data
plt.xlabel('酒精浓度')
plt.ylabel('颜色深度')
plt.legend(loc='lower right')
plt.savefig('葡萄酒样本.png')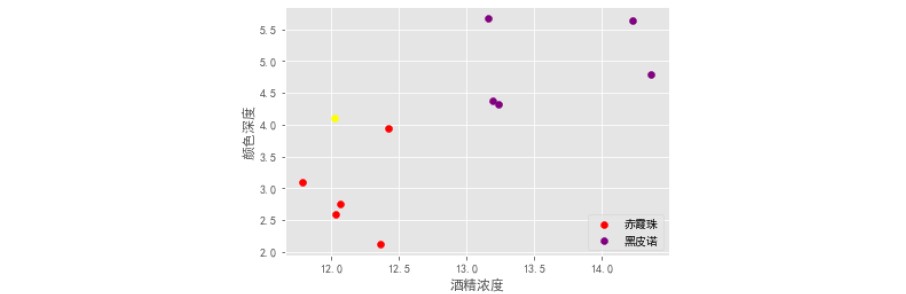
~~~ # 计算已知类别数据集中的点与当前点之间的距离
~~~ 我们使用欧式距离公式,计算新数据点 new_data 与现存的 X 数据集每一个点的距离:
from math import sqrt
distance = [sqrt(np.sum((x-new_data)**2)) for x in X ]
distance
~~~ # 将距离升序排列,然后选取距离最小的k个点
sort_dist = np.argsort(distance)
sort_dist
~~~ # 输出参数
array([6, 7, 1, 4, 5, 9, 2, 8, 3, 0], dtype=int64)~~~ # 6、7、4为最近的3个“数据点”的索引值,那么这些索引值对应的原数据的标签是什么?
k = 3
topK = [y[i] for i in sort_dist[:k]]
topK
~~~ # 输出参数
[1,1,0]~~~ # 确定前k个点所在类别的计数
pd.Series(topK).value_counts().index[0]
~~~ # 输出参数
1~~~ # 将上述过程封装成一个函数
def KNN(new_data,dataSet,k):
'''
函数功能:KNN分类器
参数说明:
new_data: 需要预测分类的数据集
dataSet: 已知分类标签的数据集
k: k-近邻算法参数,选择距离最小的k个点
return:
result: 分类结果
'''
from math import sqrt
from collections import Counter
import numpy as np
import pandas as pd
result = []
distance = [sqrt(np.sum((x-new_data)**2)) for x in
np.array(dataSet.iloc[:,0:2])]
sort_dist = np.argsort(distance)
topK = [dataSet.iloc[:,-1][i] for i in sort_dist[:k]]
result.append(pd.Series(topK).value_counts().index[0])
return result~~~ # 测试函数的运行结果
new_data=np.array([12.03,4.1])
k = 3
KNN(new_data,wine_data,k)
[1]五、SCIKIT-LEARN算法库实现
### --- SCIKIT-LEARN算法库实现
~~~ scikit-learn 自 2007 年发布以来,scikit-learn已经成为 Python 中重要的机器学习库了。scikit-learn,
~~~ 简称 sklearn, 支持了包括分类、回归、降维和聚类四大机器学习算法,
~~~ 以及特征提取、数据预处理和模型评估三大模块。
~~~ 在工程应用中,用 Python 手写代码来从头实现一个算法的可能性非常低,
~~~ 这样不仅耗时耗力,还不一 定能够写出构架清晰,稳定性强的模型。
~~~ 更多情况下,是分析采集到的数据,根据数据特征选择适合的算法,
~~~ 在工具包中调用算法,调整算法的参数,获取需要的信息,从而实现算法效率和效果之间的平衡。
~~~ 而 sklearn, 正是这样一个可以帮助我们高效实现算法应用的工具包。
~~~ http://scikit-learn.org/stable/index.html### --- 主要设计原则:
### --- 一致性
~~~ # 所有对象共享一个简单一致的界面(接口)。
~~~ # 估算器:
~~~ fit()方法。基于数据估算参数的任意对象,
~~~ 使用的参数是一个数据集(对应 X, 有监督算法还需要一个 y),
~~~ 引导估算过程的任意其他参数称为超参数,必须被设置为实例变量。~~~ # 转换器:
~~~ transform()方法。使用估算器转换数据集,转换过程依赖于学习参数。
~~~ 可以使用便捷方式: fit_transform(),相当于先 fit()再 transform()。
~~~ (fit_transform 有时被优化过,速度更快)
~~~ # 预测器:
~~~ predict()方法。使用估算器预测新数据,返回包含预测结果的数据,
~~~ 还有score()方法:用于度量给定测试集的预测效果的好坏。
~~~ (连续 y 使用 R 方,分类 y 使用准确率 accuracy)### --- 监控
~~~ 检查所有参数,所有估算器的超参数可以通过公共实例变量访问,
~~~ 所有估算器的学习参数都可以通过有下划线后缀的公共实例变量访问。
### --- 防止类扩散
~~~ 对象类型固定,数据集被表示为 Numpy 数组或 Scipy 稀疏矩阵,
~~~ 超参是普通的 Python 字符或数字。### --- 合成
~~~ 现有的构件尽可能重用,可以轻松创建一个流水线 Pipeline。
### --- 合理默认值
~~~ 大多数参数提供合理默认值,可以轻松搭建一个基本的工作系统### --- 案例一:红酒
from sklearn.neighbors import KNeighborsClassifier
# 0 代表 “黑皮诺”,1 代表 “赤霞珠”
clf = KNeighborsClassifier(n_neighbors = 3)
clf = clf.fit(wine_data.iloc[:,0:2], wine_data.iloc[:,-1])
result = clf.predict([[12.8,4.1]]) # 返回预测的标签
result
~~~ # 输出参数
array([0])### -- 对模型进行一个评估,接口score返回预测的准确率
score = clf.score([[12.8,4.1]],[0])
score
~~~ # 输出参数
1.0clf.predict_proba([[12.8,4.1]])
#输出数据[12.8,4.1]为标签0的概率(0.666...),以及标签为1的概率(0.333...)
~~~ # 输出参数
array([[0.66666667, 0.33333333]])### --- 案例二:乳腺癌
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
#读取数据集
data = load_breast_cancer()
#DateFrame格式显示
X = data.data
y = data.target
name = ['平均半径','平均纹理','平均周长','平均面积',
'平均光滑度','平均紧凑度','平均凹度',
'平均凹点','平均对称','平均分形维数',
'半径误差','纹理误差','周长误差','面积误差',
'平滑度误差','紧凑度误差','凹度误差',
'凹点误差','对称误差',
'分形维数误差','最差半径','最差纹理',
'最差的边界','最差的区域','最差的平滑度',
'最差的紧凑性','最差的凹陷','最差的凹点',
'最差的对称性','最差的分形维数','患病否']
data=np.concatenate((X,y.reshape(-1,1)),axis=1)
table=pd.DataFrame(data=data,columns=name)
table.head()### --- 划分训练集和测试集 #30%数据作为训练集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=420)
# 建立模型&评估模型
clf = KNeighborsClassifier(n_neighbors=4)
# 建立分类器
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score
~~~ # 输出参数
0.9210526315789473### --- 如何用上面分类器拟合结果找出离 Xtest 中第 20 行和第 30 行最近的 4 个“点”?
~~~ # 查找点的K邻居。返回每个点的邻居的与之的距离和索引值。
clf.kneighbors(Xtest[[20,30],:],return_distance=True)
(array([[35.70015941, 42.02374599, 81.82147557, 83.06271326],
[11.81126721, 14.5871725 , 17.4734004 , 18.94892695]]),
array([[112, 221, 303, 263], [268, 162, 42, 134]], dtype=int64))Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor










